
实习生日薪 5500 元,清华姚班凭什么成为 AI 圈的「硬通货」
实习生日薪 5500 元,清华姚班凭什么成为 AI 圈的「硬通货」最近,DeepSeek 接连上了几次热搜。先是因为一张实习 offer 引发围观。一位清华学生在社交媒体晒出录用信息,岗位是 DeepSeek 实习生,税前日薪 5500 元。按每月 22 个工作日计算,月薪超过 12 万元。
来自主题: AI资讯
8937 点击 2026-07-25 21:16
 搜索
搜索
最近,DeepSeek 接连上了几次热搜。先是因为一张实习 offer 引发围观。一位清华学生在社交媒体晒出录用信息,岗位是 DeepSeek 实习生,税前日薪 5500 元。按每月 22 个工作日计算,月薪超过 12 万元。

@elsewhere 上个月,「elsewhere」报道了 DeepSeek 的融资故事。其中最多人讨论的,莫过于那个传说中的4小时投资人会议。 此去一个月间,梁文锋的各种语录在江湖流传,我们也多方收集到了一些其中内容。
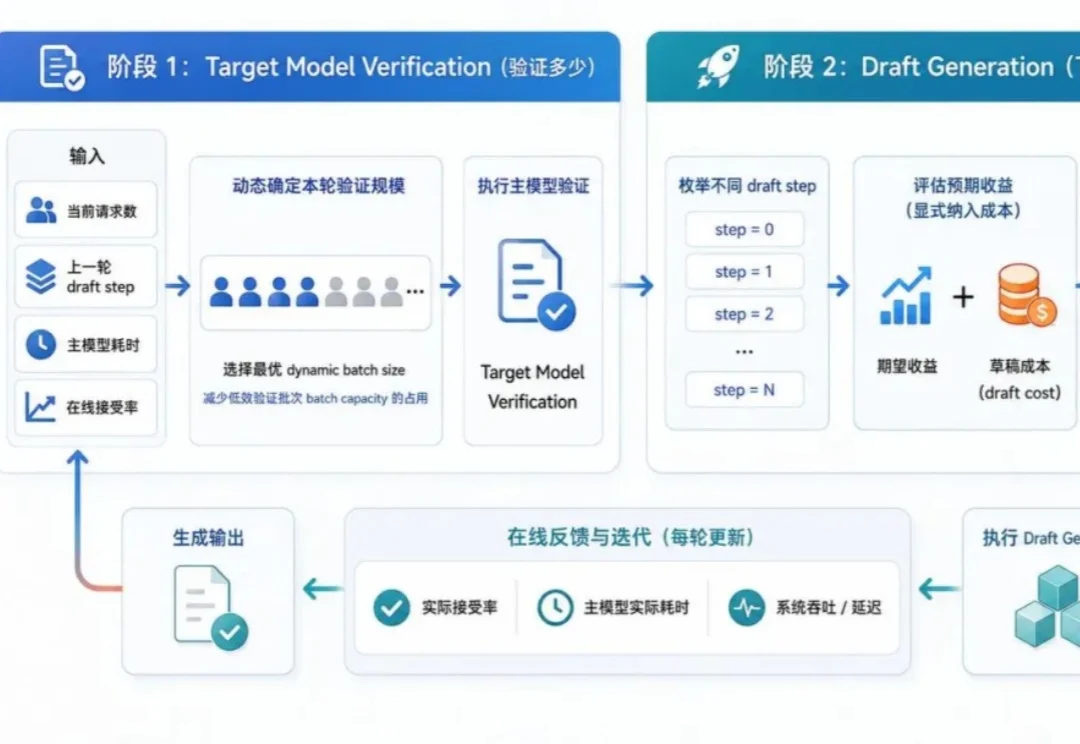
随着 DeepSeek 发布 DSpark,动态 MTP(多 Token 预测)成为了对抗高并发、提升 GPU 利用率的绝对焦点。然而,DSpark 高度绑定特定模型且需要额外训练。

过去 12 个小时,关于 DeepSeek 的消息一个接一个炸出来。

月之暗面旗下新一代大模型 Kimi K3 已由员工在 X 上确认,将于本月内发布。据多方信源,K3 的参数规模将达到 2.5 万亿——这一数字不仅超越了 DeepSeek V4 Pro 的 1.6 万亿,也成为当前已公开参数规模最大的国产模型。

你有没有想过一个问题: 我们平时选模型,到底有多少是因为它真的好用,又有多少是因为它便宜?
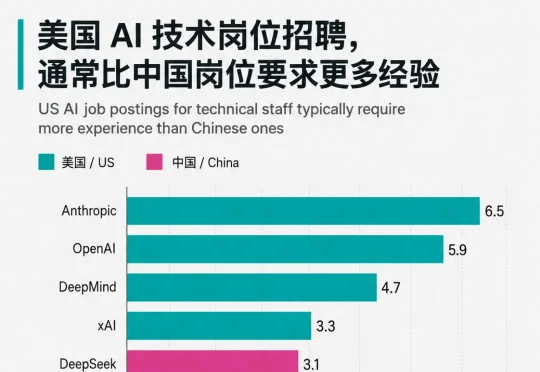
同样是进顶尖 AI 公司当工程师,在中国你只要 1.6 年经验,在美国却得熬到 5.5 年。换句话说,一个中国应届生刚拿到毕业证,就可能坐在 DeepSeek 的工位上调大模型;而他的美国同行还得在别的公司再「实习」四年,才够格投一份前沿 AI 实验室的简历。

斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。

关于 DeepSeek 的融资信息,已经漫天遍野。已知信息,「elsewhere」不再赘述。以下,是我们了解到的一些未被展示过的故事或情节。先说那场投资人会议,也就是那个口耳相传的“四小时会议”。
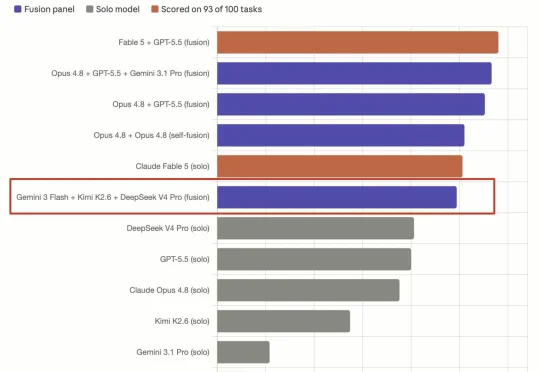
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。